更新履歴
- 【Git】コンフリクト解消はもう怖くない!現場で迷わない具体的な手順
- PEMとPPKの違いを解説!使い分けとPuTTYでの変換手順まとめ
- 【1分で解決】リモートデスクトップでタスクバーが隠れる時の対処法
- 【Git】複数のコミットを一つにまとめる|squash/fixupで履歴を整える
- ダックタイピングとは?「アヒルのように鳴くならアヒル」をわかりやすく解説
- crontabファイルの場所はどこ?OS別の保存先パスと確認・編集方法を徹底解説
- 【pytest】特定のテストだけを実行する方法!ファイル・クラス・関数ごとに解説
- TeraTermのセッションが勝手に切れる原因と対策|タイムアウトを防ぐ設定ガイド
- WinMergeをインストール不要で使う!ポータブル版の導入手順とメリットを解説
- 【完全ガイド】WinMergeでバイナリ比較をする方法
- SwaggerとOpenAPIの違いを徹底解説!仕様とツールの関係性を理解する
- 【Python】ファイル存在チェックの実装方法(pathlib、os.path)
- Pythonで文字列を除去する方法を完全解説!strip・replace・正規表現
- スタック領域とヒープ領域の違いとは?メモリ管理から使い分けまで徹底解説
- Python Docstringの書き方完全ガイド|主要スタイルの比較と保守性を高める記述
- シングルトンのJava実装と活用ガイド!メリット・デメリット・アンチパターンを徹底解説
- サインインとログインの違いとは?意味・使い分けをわかりやすく解説
- 静的サイトと動的サイトの違いを徹底比較!メリット・デメリットと選び方を解説
- モノリスとマイクロサービスの違いを比較|メリット・デメリットと選定基準
- RESTとSOAPの違いを徹底比較!特徴・メリット・使い分けを解説
お役立ちツール
Oracleのおすすめ
![図解入門よくわかる 最新Oracleデータベースの基本と仕組み[第6版]](https://m.media-amazon.com/images/I/81mwLGJmsqL._SL1500_.jpg)
Oracleユーザにお勧めの本


ストレス社会で働くITエンジニアの休息に

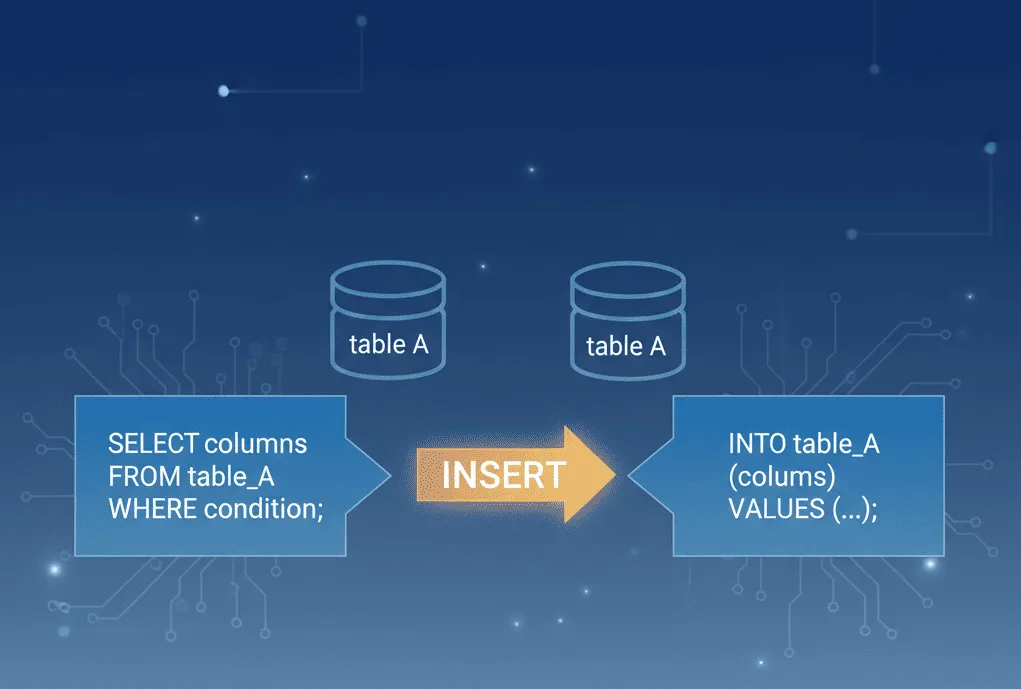
Oracleデータベースにおいて、INSERT INTO ... SELECT構文を使うことで、既存データを元に新しいデータを同じテーブルへ挿入することが可能です。例えば、売上データの複製や過去データの履歴化、または既存データをベースに派生データを生成するシナリオにおいてよく用いられます。同じテーブルを対象とする場合は注意が必要ですが、効率的に活用すれば業務処理の自動化や高速化に大きく寄与します。
前提:テーブル定義とサンプルデータ
本記事は以下データを前提に解説します。
サンプルDDL(クリックで開く)
-- テーブル作成: 部署テーブルCREATE TABLE departments ( dept_id NUMBER PRIMARY KEY, dept_name VARCHAR2(100), base_salary NUMBER(10,2));
-- テーブル作成: 従業員テーブルCREATE TABLE employees ( emp_id NUMBER PRIMARY KEY, emp_name VARCHAR2(100), salary NUMBER(10,2), dept_id NUMBER REFERENCES departments(dept_id), created_at DATE DEFAULT SYSDATE);
-- テーブル作成: usersテーブルCREATE TABLE users ( user_id NUMBER PRIMARY KEY, name VARCHAR2(50), status VARCHAR2(20));
-- テーブル作成: audit_logテーブルCREATE TABLE audit_log ( user_id NUMBER, action VARCHAR2(20), logtime DATE);
-- テーブル作成: report_logテーブルCREATE TABLE report_log ( user_id NUMBER, result VARCHAR2(20), logtime DATE);
-- テーブル作成: high_salaryテーブルCREATE TABLE high_salary (id NUMBER,name VARCHAR2(50));
-- テーブル作成: low_salaryテーブルCREATE TABLE low_salary (id NUMBER,name VARCHAR2(50));
-- サンプルデータ投入: 部署INSERT INTO departments (dept_id, dept_name, base_salary) VALUES (10, 'Sales', '3000');INSERT INTO departments (dept_id, dept_name, base_salary) VALUES (20, 'HR', '4000');INSERT INTO departments (dept_id, dept_name, base_salary) VALUES (30, 'IT', '5000');
-- サンプルデータ投入: 従業員INSERT INTO employees (emp_id, emp_name, salary, dept_id, created_at)VALUES (1, 'Alice', 5000, 10, TO_DATE('2023-06-01','YYYY-MM-DD'));
INSERT INTO employees (emp_id, emp_name, salary, dept_id, created_at)VALUES (2, 'Bob', 4500, 10, TO_DATE('2023-09-15','YYYY-MM-DD'));
INSERT INTO employees (emp_id, emp_name, salary, dept_id, created_at)VALUES (3, 'Charlie', 6000, 20, TO_DATE('2024-02-20','YYYY-MM-DD'));
INSERT INTO employees (emp_id, emp_name, salary, dept_id, created_at)VALUES (4, 'Diana', 7000, 30, TO_DATE('2024-05-10','YYYY-MM-DD'));
-- サンプルデータ投入:usersINSERT INTO users VALUES (101, 'User_A', 'ACTIVE');INSERT INTO users VALUES (102, 'User_B', 'INACTIVE');INSERT INTO users VALUES (103, 'User_C', 'ACTIVE');INSERT INTO users VALUES (104, 'User_D', 'ACTIVE');
COMMIT;テーブルデータ(クリックで開く)
departments
| DEPT_ID | DEPT_NAME | BASE_SALARY |
|---|---|---|
| 10 | Sales | 3000.00 |
| 20 | HR | 4000.00 |
| 30 | IT | 5000.00 |
employees
| EMP_ID | EMP_NAME | SALARY | DEPT_ID | CREATED_AT |
|---|---|---|---|---|
| 1 | Alice | 5000.00 | 10 | 2023/06/01 0:00:00 |
| 2 | Bob | 4500.00 | 10 | 2023/09/15 0:00:00 |
| 3 | Charlie | 6000.00 | 20 | 2024/02/20 0:00:00 |
| 4 | Diana | 7000.00 | 30 | 2024/05/10 0:00:00 |
users
| USER_ID | NAME | STATUS |
|---|---|---|
| 101 | User_A | ACTIVE |
| 102 | User_B | INACTIVE |
| 103 | User_C | ACTIVE |
| 104 | User_D | ACTIVE |
SELECT結果を同一テーブルへINSERTする
INSERT INTO … SELECT 文の基本と同一テーブルへの適用
最もシンプルな構文は以下の通りです。
INSERT INTO employees (emp_id, emp_name, salary, dept_id)SELECT emp_id + 1000, emp_name, salary * 1.1, dept_idFROM employeesWHERE dept_id = '10';employeesの登録データ例
| EMP_ID | EMP_NAME | SALARY | DEPT_ID | CREATED_AT |
|---|---|---|---|---|
| 1001 | Alice | 5500.00 | 10 | 2025/09/23 20:12:09 |
| 1002 | Bob | 4950.00 | 10 | 2025/09/23 20:12:09 |
-
ポイント:
SELECT句で数値計算や文字列結合を行い、データを加工して挿入できます。WHERE句により、対象データを絞り込んで不要な挿入を避けられます。
複数のテーブルを結合した上でのINSERTも可能です。
INSERT INTO employees (emp_id, emp_name, salary, dept_id)SELECT e.emp_id + 2000, e.emp_name, d.base_salary, e.dept_idFROM employees eJOIN departments d ON e.dept_id = d.dept_id;employeesの登録データ例
| EMP_ID | EMP_NAME | SALARY | DEPT_ID | CREATED_AT |
|---|---|---|---|---|
| 2001 | Alice | 3000.00 | 10 | 2025/09/23 20:12:37 |
| 2002 | Bob | 3000.00 | 10 | 2025/09/23 20:12:37 |
| 2003 | Charlie | 4000.00 | 20 | 2025/09/23 20:12:37 |
| 2004 | Diana | 5000.00 | 30 | 2025/09/23 20:12:37 |
| 3001 | Alice | 3000.00 | 10 | 2025/09/23 20:12:37 |
| 3002 | Bob | 3000.00 | 10 | 2025/09/23 20:12:37 |
このようにJOINを組み合わせることで、別テーブルの属性を参照しながら効率的にデータを生成できます。



INSERT ALLによる複数行挿入
複数のINSERTをまとめて実行できます。条件が複数に一致する場合はすべて適用されます。
INSERT ALL INTO audit_log VALUES (user_id, 'INSERTED', sysdate) INTO report_log VALUES (user_id, 'OK', sysdate)SELECT user_id FROM users WHERE status = 'ACTIVE';audit_logの登録データ例
| USER_ID | ACTION | LOGTIME |
|---|---|---|
| 101 | INSERTED | 2025/09/23 20:18:00 |
| 103 | INSERTED | 2025/09/23 20:18:00 |
| 104 | INSERTED | 2025/09/23 20:18:00 |
report_logの登録データ例
| USER_ID | RESULT | LOGTIME |
|---|---|---|
| 101 | OK | 2025/09/23 20:18:00 |
| 103 | OK | 2025/09/23 20:18:00 |
| 104 | OK | 2025/09/23 20:18:00 |
INSERT FIRSTによる複数行挿入
条件に一致した最初のものだけを評価してINSERTする構文です。
INSERT FIRST WHEN salary > 5000 THEN INTO high_salary VALUES (emp_id, emp_name) WHEN salary <= 5000 THEN INTO low_salary VALUES (emp_id, emp_name)SELECT emp_id, emp_name, salary FROM employees;high_salaryの登録データ例
| ID | NAME |
|---|---|
| 3 | Charlie |
| 4 | Diana |
| 1001 | Alice |
low_salaryの登録データ例
| ID | NAME |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 1002 | Bob |
| 2001 | Alice |
| 2002 | Bob |
| 2003 | Charlie |
| 2004 | Diana |
| 3001 | Alice |
| 3002 | Bob |
これにより、条件分岐による振り分けINSERTが容易になります。
Oracleユーザにお勧めの本
以上で本記事の解説を終わります。
よいITライフを!