Pythonユーザにお勧めの本 ↗

スッキリわかるPython入門 第2版 スッキリわかるシリーズ
対話形式でスラスラ読める。複雑な概念もキャラクターが分かりやすく解説してくれます。

言語仕様を深く解説。なんとなく書ける状態から、自信を持って書ける状態へ引き上げてくれます。

Python1年生 第2版 体験してわかる!会話でまなべる!プログラミングのしくみ
イラスト中心で、プログラミングの楽しさを教えてくれる。ワクワクしながら学べる入門書です。
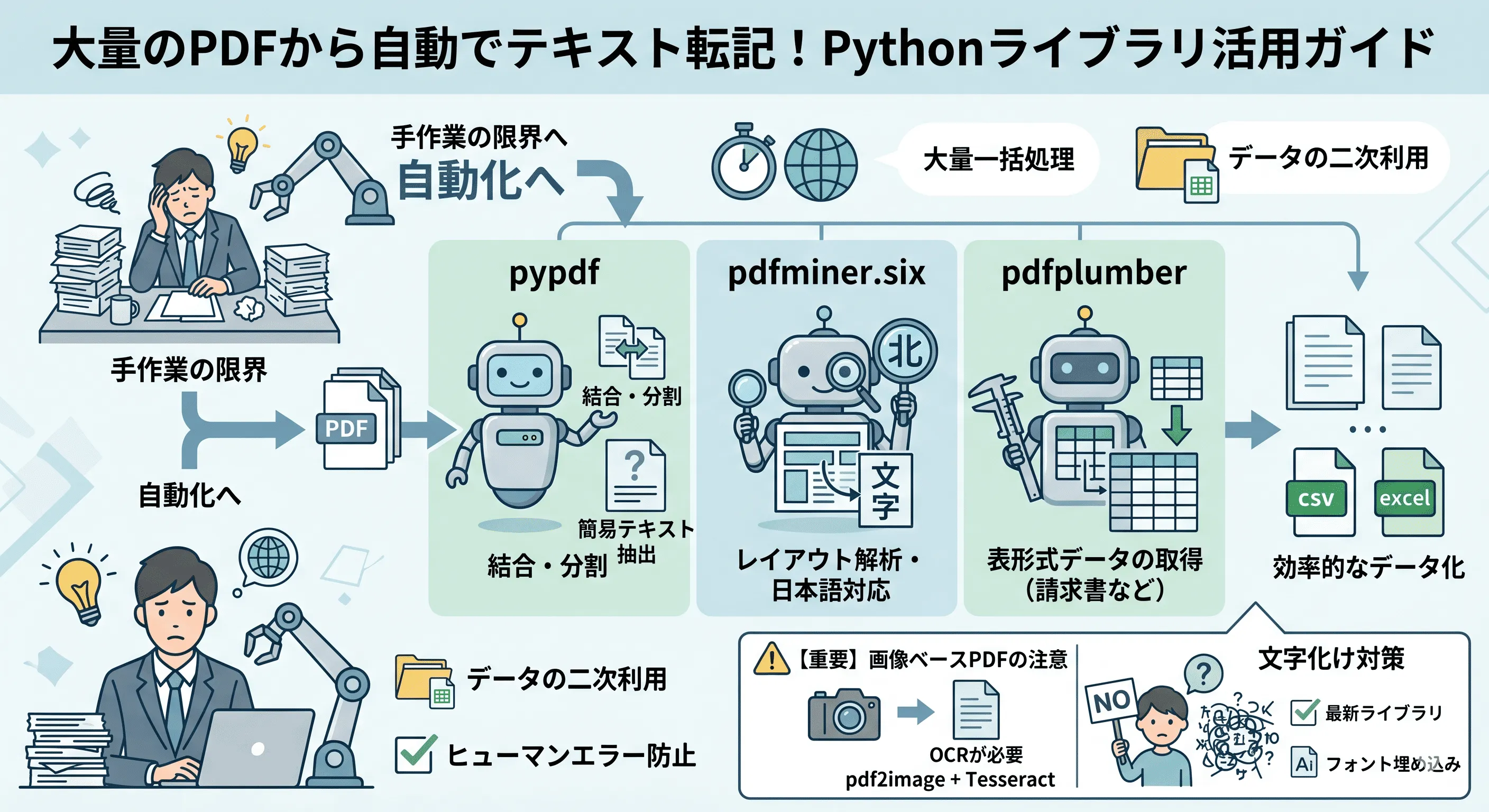
大量のPDFから手作業でテキストを転記する作業に、限界を感じていませんか?PythonPython [パイソン]汎用プログラミング言語でPDFのテキスト抽出効率化を図りたくても、ライブラリの選定や日本語の文字化け対策に悩む方は多いはずです。
本記事では、実務で役立つ主要ライブラリの比較から、具体的なコード例まで徹底解説します。この記事を読めば、あなたの業務に最適な抽出手法がマスターでき、自動化の第一歩を踏み出せます。
記事のポイント
- 抽出したいデータの種類(表・テキスト)に合わせて、pdfminer.sixやpdfplumberなどの最適なライブラリを選定できます。
- 実務で役立つ具体的なコード例を通じて、日本語の文字化け対策や表形式データの効率的な抽出テクニックを習得できます。
- パスワード保護への対応や大量ファイルの高速処理など、開発現場で直面しやすい課題の解決策がわかります。
PythonでPDFテキスト抽出を行うべき理由と最適なライブラリの選び方
ビジネスシーンで広く利用されるPDFファイルですが、その内容をコピー&ペーストして別の資料にまとめ直す作業は、非常に手間がかかるものです。Pythonを活用して PDFからテキストを自動抽出 することで、手作業によるミスを減らし、業務の生産性を大幅に向上させることが期待できます。ここでは、Pythonを用いる利点と、目的に応じたライブラリの選び方を解説します。
業務効率化を加速させるPythonによるPDFテキスト抽出のメリット
PythonでPDF操作を自動化することには、以下のような多くの メリット があります。
- 大量のファイルを一括処理 :数百、数千のPDFファイルから必要な情報を条件次第では短時間で一括処理が可能です(数分〜数十分程度が一般的)。
- データの二次利用が容易 :抽出したテキストをCSVCSV [シーエスブイ]Comma-Separated Values。カンマ区切りのデータ形式やExcel、データベースへ直接保存し、分析に活用できます。
- ヒューマンエラーの防止 :手入力による転記ミスを排除し、データの正確性を保つことに貢献します。
ルーチンワークをプログラムに任せることで、よりクリエイティブな業務に時間を割くことが可能になるかもしれません。
目的別で選ぶ!主要なPythonライブラリ(pypdf, pdfminer.six, pdfplumber)の特徴比較
PythonにはPDF操作のためのライブラリが豊富に揃っていますが、それぞれ得意分野が異なります。以下の比較表を参考に、プロジェクトに最適なツールを選定してください。
| ライブラリ名 | 特徴 | おすすめのケース |
|---|---|---|
| pypdf | 外部依存がなく導入が容易。PDFの結合や分割、回転などが得意。 | 簡易的なテキスト抽出(精度は限定的) |
| pdfminer.six | レイアウト解析に優れ、文字の位置情報も取得可能。 | 日本語対応に比較的強いが、PDFの内部構造に依存する |
| pdfplumber | pdfminer.six をベースに、表の抽出に特化。 | 請求書や名簿などの表形式データの取得 |
例えば、単に文字を抜き出したいだけであれば pypdf が手軽ですが、日本語の精度やレイアウトを重視する場合は pdfminer.six の採用が有力な選択肢になります。
テキスト抽出が可能なPDFの確認
PDFからテキストを抽出する際、そのPDFが内部に文字情報を持っているかを確認することが重要です。WordやPowerPointから保存されたテキストベースのPDFであれば、上述のライブラリを使用することで 比較的高い精度でテキストを抽出 できるケースが多いです。
対象となるPDFの性質を正しく理解することが、実装を成功させるための第一歩と言えるでしょう。
[!IMPORTANT] スキャンされたPDF(画像ベース)は通常のライブラリではテキスト抽出できません。 その場合はOCR(例:Tesseract)を使用する必要があります。OCRを使用する場合は、PDFを画像に変換(例:pdf2image)した上で処理するのが一般的です。なお、OCRはレイアウトや精度が不安定なため、後処理(整形・補正)が必要になるケースが多い点にも注意が必要です。本記事ではテキスト情報を保持しているPDFを対象に解説します。
実践!Pythonライブラリを使ったPDFテキスト抽出の具体的な実装手順
PDFからテキストを抽出するための具体的なコード例を紹介します。環境構築から、表データの取得まで、ステップバイステップで解説します。
pdfminer.sixを使って正確にテキストを抽出する基本コード
pdfminer.six は、PDFの内部構造を解析してテキストを抽出するのに広く利用されている代表的なライブラリです。まずはライブラリをインストールしましょう。
pip install pdfminer.six以下は、基本的なテキスト抽出のコードです。
from pdfminer.high_level import extract_text
text = extract_text('sample.pdf')print(text)このライブラリは、文字の位置情報を保持しながら解析を行うため、 レイアウトが複雑なドキュメント でも比較的高い精度でテキストを取得できる傾向があります。
pdfplumberで表形式のデータを含むPDFからテキストを抽出するテクニック
請求書や名簿など、PDF内の「表」を構造化データとして取得したい場合には pdfplumber が非常に便利です。まずはライブラリをインストールしましょう。
pip install pdfplumberimport pdfplumber
with pdfplumber.open("table_sample.pdf") as pdf: # 1ページ目を選択 page = pdf.pages[0] # 表を抽出 table = page.extract_table() for row in table: print(row)extract_table() メソッドを使用することで、表のセルをリスト形式で取得できます。これを Pandaspandas [パンダス]Pythonでデータ解析を支援する強力なデータ構造操作ライブラリ(データ分析ライブラリ) のDataFrameに変換すれば、その後のデータ分析もスムーズに行えるでしょう。
日本語PDFの文字化けを防ぐための文字コード・フォント依存の注意点
日本語のPDFを扱う際、最も頻繁に遭遇するのが 文字化け の問題です。PDFの文字化けは、一般的なテキストファイルのようにエンコーディングを指定して解決するケースは少なく、フォント情報や内部構造に依存します。これを防ぐためには、以下の点に注意すると良いでしょう。
- 最新のライブラリを使用する
古いライブラリは日本語の文字コード情報やフォント埋め込み(ToUnicodeマップなど)に未対応な場合があります。 - フォントの埋め込みを確認する
PDF自体にフォントが埋め込まれていない場合、正しく抽出できない、または文字化けする可能性があります。
PythonによるPDFテキスト抽出のまとめとよくある質問
今回のまとめ:振り返りチェックリスト
- 抽出したいデータの種類に合わせて、最適なライブラリ(pdfminer.six, pdfplumber)を選択することが、開発効率と精度を両立させる鍵です。
- 日本語の文字化けを防ぐため、適切なライブラリ選びと、文字コード・フォント依存の注意点が正しく把握されているかを必ず確認しましょう。
- アドバイス: まずは手元にあるPDF1枚を使って、ライブラリごとの抽出精度の違いを実際に動かして比較することから始めましょう。その一歩が、面倒な転記作業をゼロにする自動化への大きな近道になります!
Pythonを用いたPDFからのテキスト抽出は、手作業によるデータ入力を削減し、業務効率化を飛躍的に高める可能性を秘めています。用途に合わせて最適なライブラリを選ぶことで、多様な形式のドキュメントを構造化データとして活用できるようになります。
PDF抽出の精度を最大化するためのヒント
PDFのテキスト抽出精度を向上させるためには、ライブラリの選定だけでなく、対象となるPDFの状態に合わせた工夫が求められます。
- テキスト情報の有無を事前に判別する
PDF内で文字が選択可能であれば、pdfminer.sixやpdfplumberを使用することで、元のレイアウトを維持したまま比較的自然なレイアウトで抽出できる傾向にあります。 - 座標指定による抽出の検討
特定の帳票形式であれば、pdfplumberを用いて抽出範囲を座標で指定することで、不要なヘッダーやフッターを除外し、必要なデータのみを的確に取得できる場合があります。
| 抽出対象のタイプ | 推奨されるアプローチ | 特徴 |
|---|---|---|
| 標準的なテキストPDF | pdfminer.six | 構造解析に強く、正確な抽出が期待できる |
| 表形式が含まれるPDF | pdfplumber | 境界線やレイアウトをもとに表構造を推定し、CSV化などが容易 |
よくある質問(FAQ)
PythonでのPDF操作に関して、エンジニアが直面しやすい疑問とその対策をまとめました。
Q. パスワード保護されたPDFは読み込めますか?
多くのライブラリにはパスワード解除機能が備わっています。例えば pypdf や pikepdf を使用することで、パスワードを入力して中身を解析することが可能です。ただし、権限設定によっては制限がかかる場合もあるため注意が必要です。
Q. 抽出したテキストの順番が意図せず入れ替わることがあります。
PDF内部では文字データが描画順に保存されていることがあるため、物理的な位置と一致しない場合があります。 pdfminer.six の LAParams を調整し、座標に基づいた解析を行うことで、人間が読む自然な順序に近づけられる可能性があります。
Q. 処理速度を向上させるにはどうすればよいですか?
大量のドキュメントを高速に処理したい場合は、C言語で実装されている PyMuPDF (fitz) の利用を検討してみてください。他のライブラリと比較して、高速でバランスの良い抽出が可能なケースが多いです。
参考文献
- pypdf Documentation (旧PyPDF2の公式ドキュメント)
- pdfminer.six Documentation (日本語抽出・レイアウト解析の公式ドキュメント)
- pdfplumber - GitHub Repository (表データ抽出に特化したライブラリ公式)
あわせて読みたい
Pythonの基礎から応用まで体系的に学びたい方は、以下のまとめ記事もあわせてご覧ください。

Python入門|基礎文法・環境構築・ライブラリ活用まとめ
Pythonの学習に必要な情報を網羅的にまとめた完全ガイドです。環境構築から基礎文法、オブジェクト指向、テスト、応用ライブラリまで、目的別に分かりやすく整理しています。初心者から中級者へのステップアップにぜひご活用ください。
以上で本記事の解説を終わります。
よいITライフを!
Pythonユーザにお勧めの本 ↗

「絶対に挫折させない」という著者の強い意志を感じる、プログラミングの「最初の1冊」としておすすめできる良書です。
Pythonのおすすめ
1 / 4人気記事
- 1
- 2
- 3
- 4
- 5
お役立ちツール
LINEスタンプ始めました

「絶対に挫折させない」という著者の強い意志を感じる、プログラミングの「最初の1冊」としておすすめできる良書です。