基本情報の勉強にお勧めの本 ↗

イラストが豊富で、抽象的な概念も視覚的に理解できる。試験の全体像を掴むのに最適な一冊です。

令和08年 イメージ&クレバー方式でよくわかる かやのき先生の基本情報技術者教室 情報処理技術者試験
解説が整理されていて非常に効率的。試験でよく問われる知識が確実に身につく、信頼の一冊です。
データベースは、情報を効率的に管理・検索するためのシステムであり、さまざまな用途で活用されています。特にリレーショナルデータベース(RDB)は、表形式でデータを整理し、SQLSQL [エスキューエル / シークエル]Structured Query Language。関係データベース(RDB)の管理や操作を行うデータベース言語(Structured Queryquery [クエリー / クエリ]データベースへの問い合わせ文 Language)を用いて操作するのが一般的です。本記事では非正規形~第三正規形までの正規化のやり方を具体例を用いて詳しく解説します。
データベース正規化とは?初心者向けに基礎から解説
正規化とは、データの冗長性を削減し、更新・挿入・削除時の不整合を防ぐために、関数従属性に基づいてテーブルを適切に分割する設計手法です。データを論理的に整理し、一貫性を保ちながら管理できるようにします。
非正規形から第1正規形~第5正規形までの段階が存在し、データベースの重複や矛盾を取り除くことで正規化の段階が上がります。
データベースを正規化する目的
- データの重複を減らす - 余分なデータを排除し、ストレージを効率的に使用する。
- データの一貫性を保つ - 更新・挿入・削除時の不整合を防ぐ。
- データの整合性を確保する - 論理的に意味のあるデータ構造を維持する。
- 保守性を向上させる - データ構造を整理し、変更の容易さや拡張性を向上させる。
- 設計の健全性を保つ - データの依存関係(関数従属性)を正しく整理し、無駄のないテーブル構造にする。(※ただし、正規化によってテーブルが分割されると結合(JOIN)が増えるため、必ずしも検索パフォーマンスが向上するわけではなく、むしろ低下する場合もあります)
データベース正規化のメリットとデメリット(注意点)
メリット
- データの整合性の向上:正規化により、データの一貫性が維持され、エラーの発生率が低減。
- 冗長性の削減:データの重複を防ぎ、ストレージを効率的に活用。
- データ更新の容易さ:1つのデータを変更するだけで済むため、メンテナンスが容易。
- 保守性の向上:データ構造が整理され、将来的なシステム変更に対応しやすくなる。
デメリット
- クエリの複雑化:テーブルの分割により、複雑な結合(JOIN)が必要になる。
- パフォーマンスの低下:結合回数が増えることで、検索速度が遅くなる可能性がある。
- 設計の難易度が上がる:適切な正規化を行うためには、データの関係を深く理解する必要がある。
データベース正規形の種類とやり方を具体例で解説
正規化には、いくつかの段階(正規形)が存在し、それぞれの段階でデータの整理度が高まります。
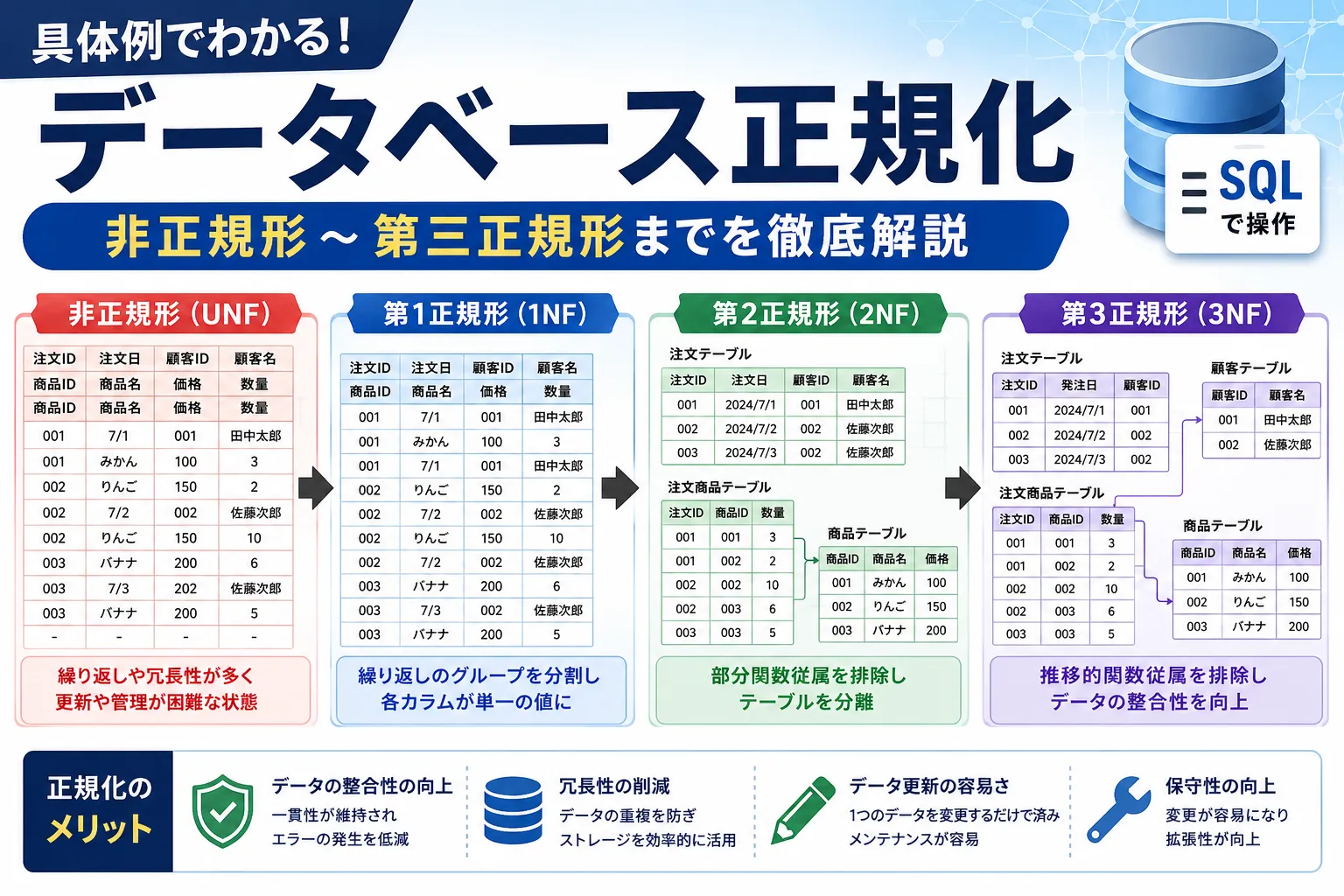
非正規形(UNF)の特徴と具体例
正規化を行っていない状態(非正規形)では、データが適切に整理されておらず、冗長性や不整合が生じやすくなります。
例:非正規形のテーブル
注文テーブル
| 注文ID | 注文日 | 顧客ID | 顧客名 | 商品ID | 商品名 | 価格 | 数量 | 商品ID | 商品名 | 価格 | 数量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 001 | 7/1 | 001 | 田中太郎 | 001 | みかん | 100 | 3 | 002 | りんご | 150 | 2 |
| 002 | 7/2 | 002 | 佐藤次郎 | 002 | りんご | 150 | 10 | 003 | バナナ | 200 | 6 |
| 003 | 7/3 | 002 | 佐藤次郎 | 003 | バナナ | 200 | 5 | - | - | - | - |
この状態では、「商品」「数量」「価格」が複数の値を持っており、検索や更新が難しくなります。データの冗長性が高いため、修正時の手間も増加し、データの一貫性を保つのが困難になります。
UNF(Unnormalized Form)は「非正規形」の略で、データがまだ正規化されていない状態を指します。UNFでは、1つのフィールドに複数の値が含まれるなど、冗長性やデータの不整合が発生しやすくなります。正規化を進めることで、データの整合性を向上させ、冗長性や更新時の不整合を削減できます。
第1正規形(1NF)のやり方と原子値の解説
第1正規形とは、各列が原子値(単一の値)を持ち、繰り返し項目や配列的な構造を排除した状態です。例では、非正規形から商品ID,商品名,価格,数量の重複を分割しています。各カラムが単一の値を持ち、非正規形のように繰り返しのグループが存在しません。
例:第1正規形のテーブル
注文テーブル
| 注文ID | 注文日 | 顧客ID | 顧客名 | 商品ID | 商品名 | 価格 | 数量 |
|---|---|---|---|---|---|---|---|
| 001 | 2024/7/1 | 001 | 田中太郎 | 001 | みかん | 100 | 3 |
| 001 | 2024/7/1 | 001 | 田中太郎 | 002 | りんご | 150 | 2 |
| 002 | 2024/7/2 | 002 | 佐藤次郎 | 002 | りんご | 150 | 10 |
| 002 | 2024/7/2 | 002 | 佐藤次郎 | 003 | バナナ | 200 | 6 |
| 003 | 2024/7/3 | 002 | 佐藤次郎 | 003 | バナナ | 200 | 5 |
NF(Normal Form)とは、データベースの正規形を示す略称です。データベースの正規化を行う際に、各段階(第一正規形: 1NF、第二正規形: 2NF、第三正規形: 3NF など)を指す際に使われます。各正規形は、データの整合性を高め、冗長性を削減し、管理しやすいデータ構造を構築するためのルールを定めています。
第2正規形(2NF)のやり方と部分関数従属の排除
第1正規形のテーブルから部分関数従属をなくした状態のことです。
部分関数従属とは、複数の列から構成される複合キー(複合主キー)に対して、その一部の列だけで決定できる項目が存在する状態のことです。
第1正規形の例では、(注文ID, 商品ID)が候補キー(主キー)である複合主キーの構成となっています。
この複合主キーのうち、注文IDのみで注文日,顧客ID,顧客名を決定でき、商品IDのみで商品名,価格が決まるという「部分関数従属」が存在するため、これらを別テーブルへと分離します。
例:第2正規形のテーブル
注文テーブル
| 注文ID | 注文日 | 顧客ID | 顧客名 |
|---|---|---|---|
| 001 | 2024/7/1 | 001 | 田中太郎 |
| 002 | 2024/7/2 | 002 | 佐藤次郎 |
| 003 | 2024/7/3 | 002 | 佐藤次郎 |
注文商品テーブル
| 注文ID | 商品ID | 数量 |
|---|---|---|
| 001 | 001 | 3 |
| 001 | 002 | 2 |
| 002 | 002 | 10 |
| 002 | 003 | 6 |
| 003 | 003 | 5 |
商品テーブル
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 001 | みかん | 100 |
| 002 | りんご | 150 |
| 003 | バナナ | 200 |
第3正規形(3NF)のやり方と推移的関数従属の排除
第3正規形とは、第2正規形のテーブルから推移的関数従属をなくした状態のことです。
推移的関数従属とは、「A→B、B→C」であるとき、結果として「A→C」が成立する依存関係のことです(主キーによって決まる項目が、さらに別の非キー項目を決定している状態を指します)。
例では注文IDによって決定される顧客IDが、さらに顧客名を決定しているため、これを別テーブルへ移します。
例:第3正規形
注文テーブル
| 注文ID | 注文日 | 顧客ID |
|---|---|---|
| 001 | 2024/7/1 | 001 |
| 002 | 2024/7/2 | 002 |
| 003 | 2024/7/3 | 002 |
顧客テーブル
| 顧客ID | 顧客名 |
|---|---|
| 001 | 田中太郎 |
| 002 | 佐藤次郎 |
注文商品テーブル
| 注文ID | 商品ID | 数量 |
|---|---|---|
| 001 | 001 | 3 |
| 001 | 002 | 2 |
| 002 | 002 | 10 |
| 002 | 003 | 6 |
| 003 | 003 | 5 |
商品テーブル
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 001 | みかん | 100 |
| 002 | りんご | 150 |
| 003 | バナナ | 200 |
その他の正規形(BCNF・第4正規形・第5正規形)
第三正規形以降はボイス・コッド、第四、第五正規形が存在します。
BCNF・第4正規形・第5正規形の概要
ボイス・コッド以降の各正規形は実務で適用されるケースが比較的特殊であるため、詳しい説明は省略しますが、概要は以下の通りです。
| 正規形 | 概要 |
|---|---|
| ボイス・コッド正規形(BCNF) | 3NFを満たし、すべての決定子がスーパーキーであることが必要。 |
| 第四正規形(4NF) | BCNFを満たし、多値従属性を排除。 1つのキーに対して複数の独立した値が関連付けられる場合、それを分離する。 |
| 第五正規形(5NF) | 4NFを満たし、結合従属性を排除。 分割されたテーブルを再結合したときに、元のデータが正しく再構築できるようにする。 |
実務におけるデータベース正規化はどこまで行うべきか?
過剰な正規化はデータ管理効率(結合クエリの複雑化やパフォーマンス低下など)が悪くなるため、実務では第3正規形までで十分なことが多く、BCNF以降は特殊なケースで適用されることが一般的です。
基本情報試験対策!データベース正規化の覚え方・語呂合わせ
情報処理技術者試験(基本情報など)では、第1正規形から第3正規形までの違いが頻出です。それぞれの「何を排除するのか」を以下の語呂合わせで覚えるのがおすすめです。
語呂合わせ「1に繰り返し、2に部分、3で推移」で試験を攻略
| 段階 | 語呂 | 排除するもの | 意味・イメージ |
|---|---|---|---|
| 第1正規形 | 1に繰り返し | テーブル内の繰り返し項目 | 1つのセルに複数の値が入っている状態をなくす。横に伸びる無駄を排除。 |
| 第2正規形 | 2に部分 | 部分関数従属 | 主キーの「一部」だけで決まる項目を別表に分ける。複合主キーのときに発生。 |
| 第3正規形 | 3で推移 | 推移的関数従属 | 「Aが決まればBが決まり、Bが決まればCが決まる」という数珠つなぎの依存関係を切り離す。 |
試験で「部分関数従属を排除するのはどれか?」と聞かれたら、「2に部分」を思い出して「第2正規形」と即答できるようになります!
基本情報技術者試験のデータベース正規化過去問演習
基本情報の過去問を解いて、理解度を深めましょう。
基本情報技術者試験ドットコムのリンクを載せておきます。
基本情報技術者平成20年秋期 午前問57
基本情報技術者平成21年春期 午前問32
基本情報技術者平成22年春期 午前問30
まとめ:データベース正規化の重要ポイント整理
- 非正規形は、1つのフィールドに複数の値が含まれたり、繰り返しグループが存在する状態のこと。
- 第1正規形は、非正規形から
繰り返しグループを排除し、各列を単一値(原子値)にした状態のこと。 - 第2正規形は、第1正規形のテーブルから
部分関数従属を除いた状態のこと。- 部分関数従属は、複数の列からなる複合主キーに対して、
一部の列だけで決定できる項目が存在する状態のこと。
- 部分関数従属は、複数の列からなる複合主キーに対して、
- 第3正規形は、第2正規形のテーブルから
推移的関数従属を除いた状態のこと。- 推移的関数従属は、
主キーによって決定される項目が、さらに別の非キー項目を決定している状態のこと。
- 推移的関数従属は、
- 実務では第3正規形までで十分なことが多く、BCNFや第4・第5正規形は特殊なケースで適用される。
以上で本記事の解説を終わります。
よいITライフを!
基本情報の勉強にお勧めの本 ↗

【令和8年度】 いちばんやさしい 基本情報技術者 絶対合格の教科書+出る順問題集
試験傾向を徹底分析。効率的な学習法と、分かりやすい図解で最短合格をサポートしてくれます。
FEのおすすめ
1 / 3人気記事
- 1
- 2
- 3
- 4
- 5



試験傾向を徹底分析。効率的な学習法と、分かりやすい図解で最短合格をサポートしてくれます。